wasmCloudArtefacts
Machine Learning with wasmCloud
These pages are supposed to document how to set up and deploy machine learning applications based on wasmCloud.
The current focus narrows any type of machine learning application to the use-case of prediction aka inferencing. Some applied examples may look like the following:
curl --silent -T ../images/cat.jpg localhost:8078/mobilenetv27/matches | jq
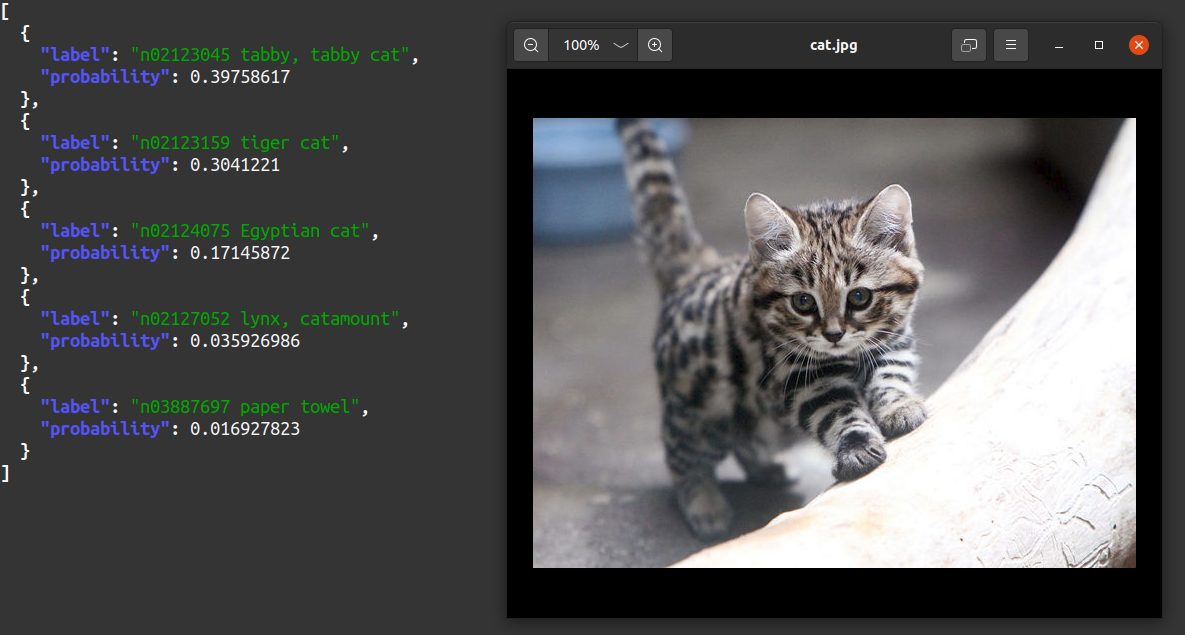 image classification with data from imagenet
image classification with data from imagenet
curl --silent -T ../images/whale.jpg localhost:8078/mobilenetv27/matches | jq
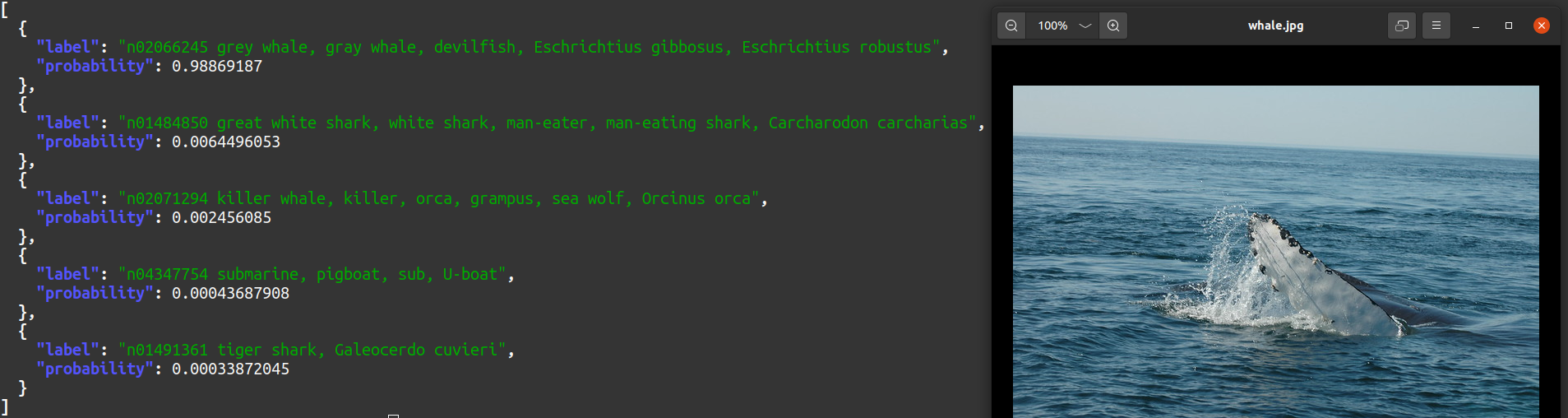 image classification with data from imagenet
image classification with data from imagenet
Structure
General architecture
In order to be able to do inferencing one has to solve other challenges as model provisioning and the deployment of application software before. Since these kinds of requirements are usually assigned to “Operations”, this is what is discussed first.
Operation’s perspective
From a high-level perspective each machine learning application in this scope comprises three different artifacts: a (wasmCloud) runtime, a (bindle) model repository and an OCI registry.
Before any deployment, the runtime does not host any application. The model repository is designed to host (binary) AI models as well as their (human readable) metadata. The OCI registry is where the business logic resides. The following screenshot roughly depicts the overall architecture.
 Application’s architecture from an operation’s point of view
Application’s architecture from an operation’s point of view
Information about the runtime, including hosted artifacts, can easily accessed via the washboard, wasmcloud’s web UI. Per default, the washboard is accessible via http://localhost:4000/ as soon as the runtime is up and running.
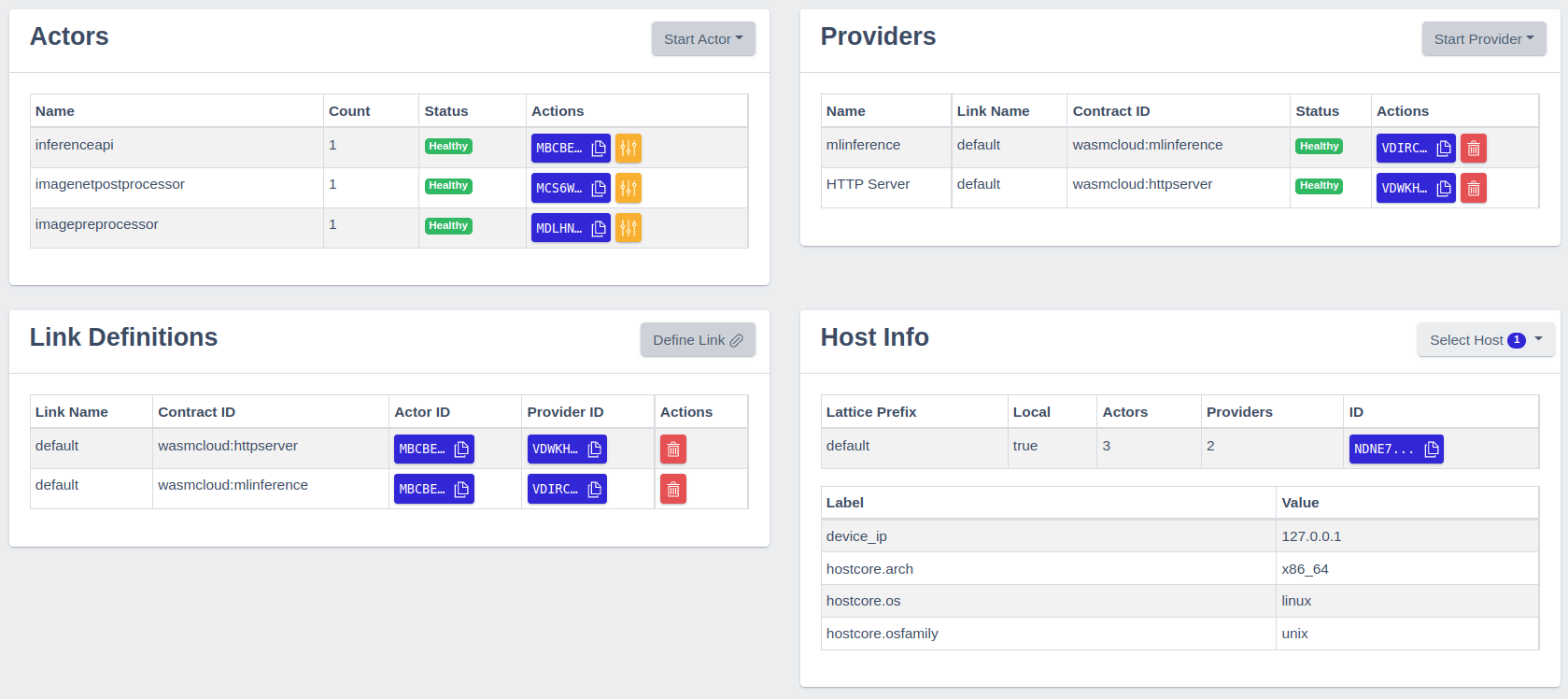 monitoring of wasmcloud’s runtime via the washboard
monitoring of wasmcloud’s runtime via the washboard
Development’s perspective
The development’s point of view focuses the runtime. There are two capability providers, https-server and mlinference as well as three actors, API, post-processor and pre-processor. The following screenshot roughly depicts the overall architecture from a developer’s perspective.
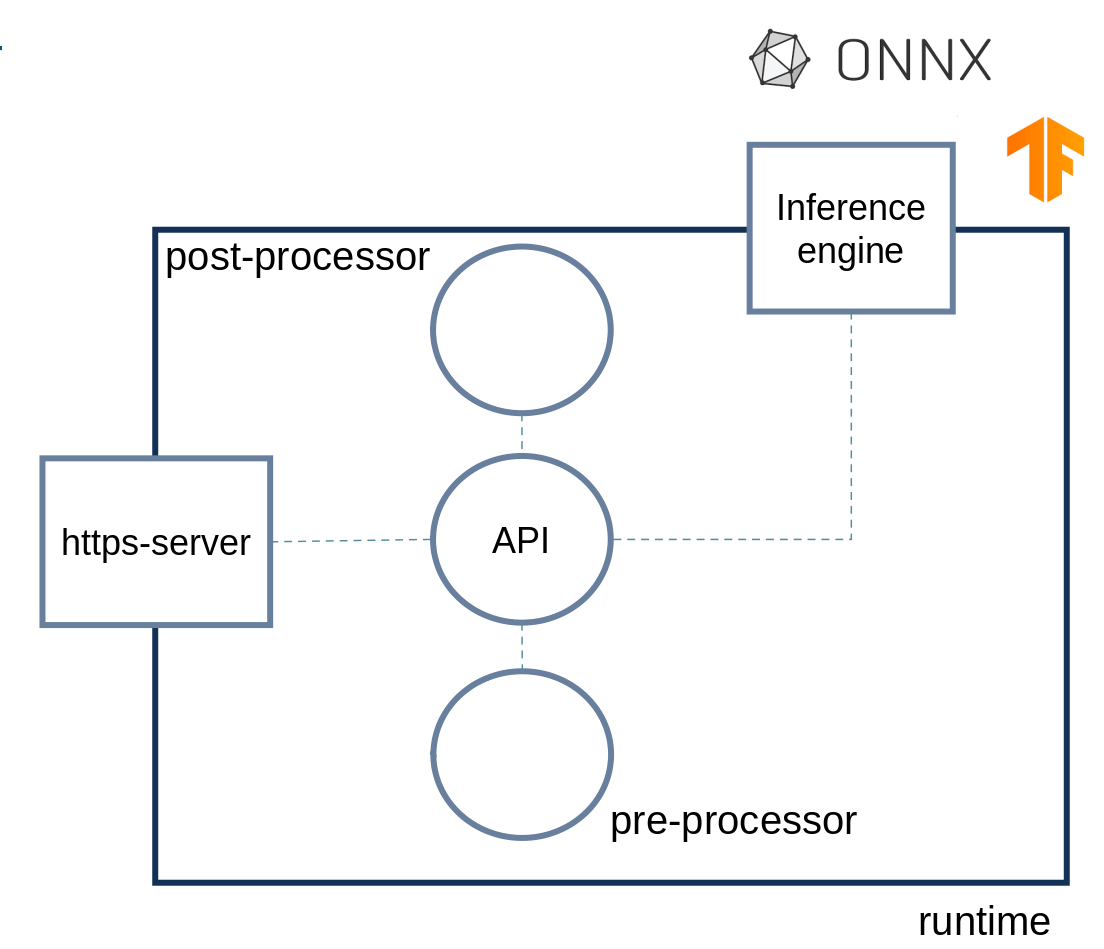 structure of a generic machine learning application
structure of a generic machine learning application
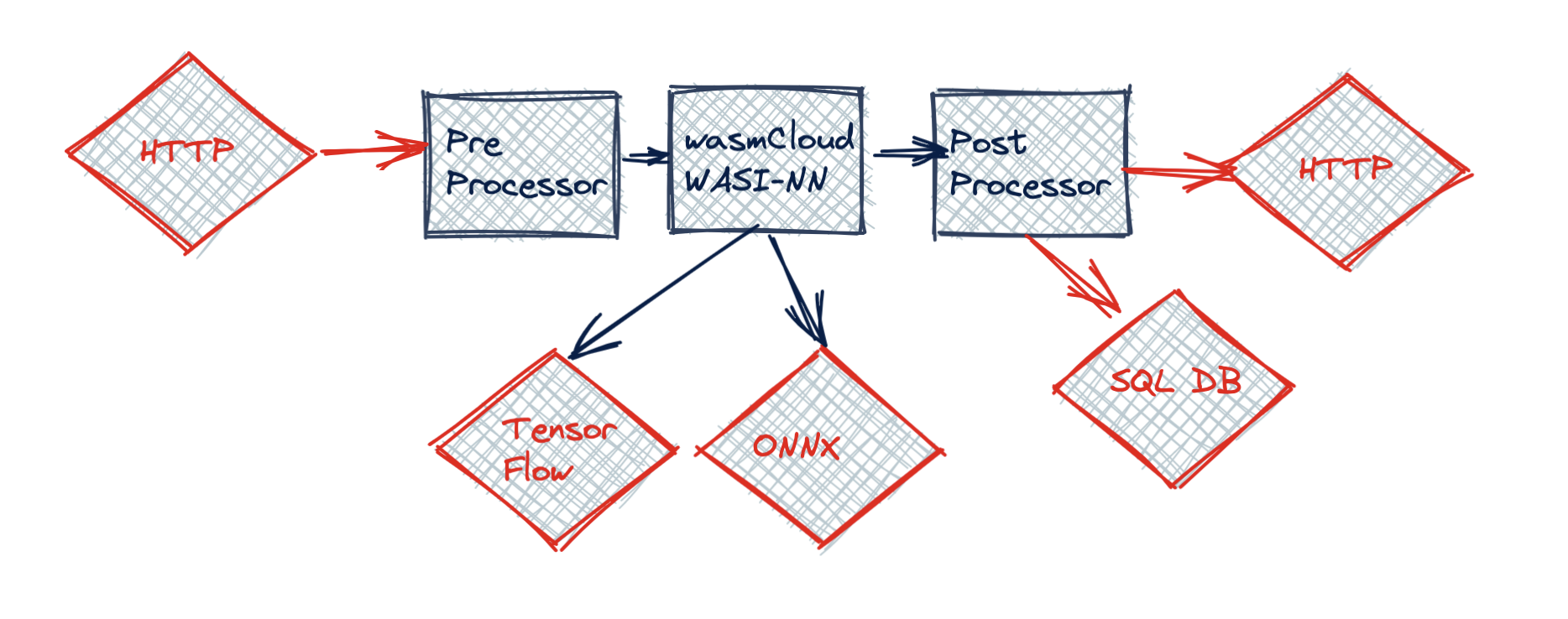 data flow
data flow
Build and Run
Prerequisites
Wasmcloud host
Download a wasmcloud host binary release for your platform from Releases
and unpack it. The path to the download folder should be set as WASMCLOUD_HOST_HOME in deploy/env.
Bindle
We recommand using bindle version v0.7.1. The latest version in github HEAD (as of March 2022) has not been released, and includes signature checks which are not compatible with the scripts in this repo.
Targets
- x86_64 Linux
- aarch64 Linux (Coral dev board)
Supported Inference Engines
The capability provider mlinference uses the amazing inference toolkit tract and currently supports the following inference engines
Preloaded Models
Once the application is up and running, start to issue requests. Currently, the repository comprises the following pre-configured models:
- identity of ONNX format
- plus3 of Tensorflow format
- mobilenetv2.7 of ONNX format
- squeezenetv1.1.7 of ONNX format
Requests against the preloaded models can be done in the following way:
# identity
curl -v POST 0.0.0.0:8078/identity -d '{"dimensions":[1,4],"valueTypes":["ValueF32"],"flags":0,"data":[0,0,128,63,0,0,0,64,0,0,64,64,0,0,128,64]}'
# plus3
curl -v POST 0.0.0.0:8078/plus3 -d '{"dimensions":[1,4],"valueTypes":["ValueF32"],"flags":0,"data":[0,0,128,63,0,0,0,64,0,0,64,64,0,0,128,64]}'
# mobilenetv2
curl --silent -T ../images/lighthouse.jpg localhost:8078/mobilenetv27/matches | jq
# squeezenetv1
curl --silent -T ../images/piano.jpg localhost:8078/squeezenetv117/matches | jq
Endpoints
The application provides three endpoints. The first endpoint routes the input tensor to the related inference engine without any pre-processing. The second endpoint pre-processes the input tensor and routes it to the related inference engine thereafter. The third performs a pre-processing before the prediction step and a post-processinging afterwards.
0.0.0.0:<port>/<model>, e.g.0.0.0.0:7078/identity0.0.0.0:<port>/<model>/preprocess, e.g.0.0.0.0:7078/squeezenetv117/preprocess0.0.0.0:<port>/<model>/matches, e.g.0.0.0.0:7078/squeezenetv117/matches
Restrictions
Concerning ONNX, see tract’s documentation for a detailed discussion of ONNX format coverage.
Concerning Tensorflow, only TensorFlow 1.x is supported, not Tensorflow 2. However, models of format Tensorflow 2 may be converted to Tensorflow 1.x. For a more detailled discussion, see the following resources:
Currently, there is no support of any accelerators like GPUs or TPUs. On the one hand, there is a range of coral devices like the Dev board supporting Tensorflow for TPU based inference. However, they only support the Tensorflow Lite derivative. For more information see Coral’s Edge TPU inferencing overview.